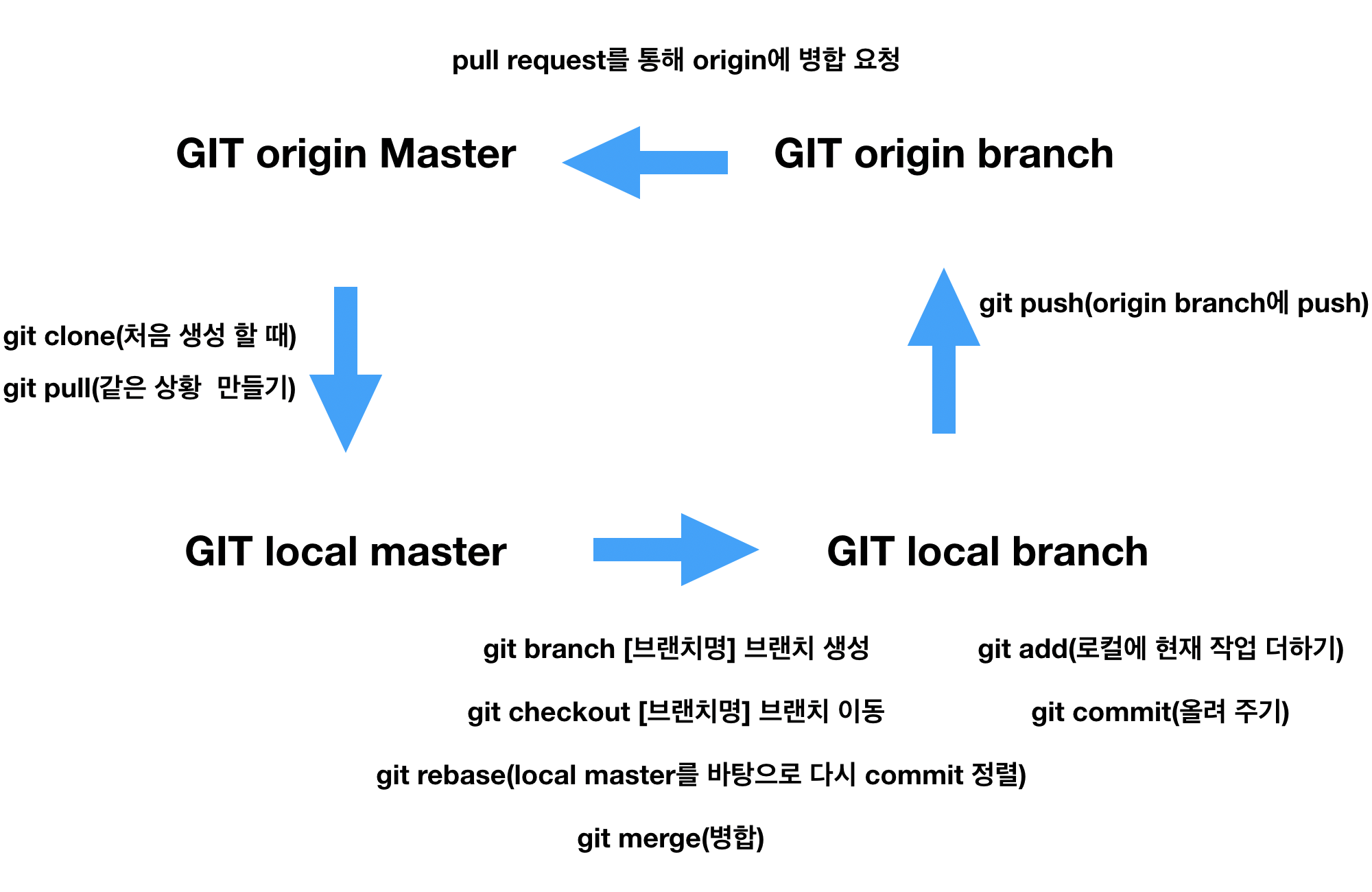
2019.01.16 javascript 변수, 조건문, 반복문, 함수, 객체, 배열
자바스크립트 기본 문법들에 대해서 배웠던 것들에 대해 다시 한번 정리하고자 한다.
변수
1. 왜 써야 하나?
컴퓨터 프로그래밍은 컴퓨터에게 어떠한 작업내용(코딩)들을 줘서 실행할 수 있도록 만드는 것이다.(나 스스로 생각...)
그 과정에서 굉장히 긴 단어(예를 들어 ㅠ=3.141592...)들을 반족해서 적어야 하는 과정들이 충분히 생길 수 있다. 심지어는 [2, 3, 4] 이렇게 여러개의 정보들을 입력해야 된다든지 그런 경우들이 충분히 생길 수 있다.
이런 경우 변수를 설정하여 간단하게 해결 할 수 있다. 따라서 변수는 굉장히 중요하다고 갑자기 적는 도중 느껴졌다.
2. 어떻게 쓰냐?
변수를 선언한다는 표현을 쓰던데
var ㅠ = 3.141592... 이라고 ㅠ를 3.141592라고 선언한 것이다.
이제 앞으로 ㅠ를 쓰게 되면 3.141592를 입력하게 된 것이고
ㅠ*10 = 31.41592가 된다. 한번 변수를 선언한 이후에는 굳이 var를 쓰지 않아도
ㅠ = 3.14 이렇게 하여서 바꿀 수 있다.
3. 추가사항
값 없이 변수 설정도 가능하다.(당장 정해지지 않았다면)
var x; 이렇게 하면 undefined로 설정이 된 것이다.
또한 원시타입이라는 것이 있는데
이 부분에 대해서는 좀 더 추가적인 공부가 필요할 것 같다.
var a = 20;
var b = a;
a = 10; 으로 했을 때 b 의 값은?
또한 변수에서는 local scope와 global scope 2가지로 나누어서 생각해야 한다.
local scope에서 적용된 변수는 global scope에서는 적용되지 않는다.
조건문
1.왜 써야 하나?
어떤 상황에서 10보다 크면 이것을 출력하고, 5보다 크면 이것을 출력하고 컴퓨터에게 어떤 작업을 하도록 시킬 때 각 상황에 대한 조건을 줘야 할 때가 많다. 그렇기 떄문에 조건문이 정말 중요하다
2.어떻게 쓰냐?
if(조건1){
조건 1이 성립될 때 실행될 코드
} else if(조건2){
조건 2가 성립될 때 실행될 코드
} else{
위에 조건들이 성립하지 않을 때 실행될 코드
}
3.추가사항
|| (or) - or와 and에서 기본은 true 이다.
&& (and)
!(not)위에 추가사항들을 활용하여
if(조건 1 || 조건2){
조건 1과 2 중 하나가 성립될 때 실행할 코드
} else if(조건1 && 조건2){
조건 1과 2 2개가 함께 성립될 때 실행할 코드
}반복문
1.왜 써야 하나?
예를 들면 1부터 100까지 정수들을 더하는 코드를 짠다고 할 때
var a = 1+2+3+4+5+......+100 이런씩으로 지속적으로 어떤 규칙들을 반복해야 할 때가 많다.
이러한 규칙들을 반복문을 통해서 쉽게 해결할 수 있다.
프로그래밍의 가장 큰 장점 중에 한개는 인간이 지속적으로 반복해야 하는 일들을 해결 해줄 수 있다는 측면에서 반복문은 굉장히 중요하다.
2.어떻게 쓰냐?
반복문에는 for와 while 2가지가 있다.
for은 여러가지 조건들을 한번에 담아서 좀 더 쉽게 쓰게 해준다.
위의 식을 for 구문으로 만들어보면
var result = 0
for(i=1; i<=100; i += 1;){
result = result + i;
}i는 1부터 시작하고 i가 100이하면 1씩 더한다.
while은 여러가지 조건들을 나열해줘야한다.
var result = 0
var i = 0
while(i<=100){
result = result + i
i += 1;
}3.추가사항
i++ 와 ++i의 차이점( 좀 더 자세히 알 필요 있음)
var result = 0
var i = 0
for(i=1; i<=100; i++){
result = result + i
}
var result = 0
var i = 1
for(i=1; i<=100; ++i){
result = result + i
}함수
1.왜 써야 하나?
함수(function)란 하나의 로직을 재실행 할 수 있도록 하는 것으로 코드의 재사용성을 높여준다.??
반복문도 어떤 코드를 한자리에서 연속적으로 반복시켜주지만
함수는 내가 필요한 여기저기 맥락안에서 언제든지 쓸 수 있음.
따라서 좋은 부품을 만드는 것.
이 함수를 사용하는 여러곳에서 처음 기본이 되는 함수를 수정하면 이 함수를 이용하는 모든 곳에서 수정, 개선 할 수 있음(이를 유지보수가 용이하다고 한다)
가독성이 좋아 질 수 있다.
재사용성, 유지보수, 가독성은 굉장히 중요하고 그 부분에서 함수는 굉장히 중요하다
2.어떻게 쓰냐?
function 함수이름(인자, 인자){
코드
return 반환값
} 이렇게 function을 설정해놓으면 함수이름을 통해서 언제든지든지 코드와 return 반환값을 불러올 수 있다.
단, return은 결과값을 불러옴과 동시에 함수를 종료시켜서 return 뒤에 나오는 것은 출력시키지 않는다.
여기서 인자는 input과 관련되며 매개변수 (parameter)라고 하며
다시 수정을 해보면
function 함수이름(매개변수){
코드
return 반환 값;
}
alert(함수이름(인자));alert해서 함수를 호출할 때 들어가는 수가 인자이고 / 위에 function을 정의하는데 들어가는 것은 매개변수이다.
3.추가사항
함수 정의 방법
numbering = function(){
코드
return 반환 값;
}- 익명 함수(이름이 필요없고 바로 실행할 때)
배열 & 객체
1.왜 써야 하나?
그릇을 담는다
배열 => 순서가 있는 값들의 모임 [a, b, c]
객체 => 각각의 정보에 대한 값들이 있는 것들을 나열 할때 {name :byeonguk, age :29, weight : 80}
배열과 객체의 가시적인 차이점은
배열은 인덱스가 자동 지정되지만 객체는 우리가 인덱스를 설정해서 지정해 줄 수 있음.
배열은 저장된 데이터들이 순서를 가지고 있음. but 객체는 key와 value 만 있음
2.어떻게 쓰냐?
배열의 선언
- var number = [1, 2, 3, 4]
특히 배열은 각자의 index 위치가 있음 0부터 시작
- num[2]; // 3
각 위치에 있는 값 바꾸기
num[2] = 15;
num[]; // [1, 2, 15, 4]
길이 확인하기
- number.length;
값 추가하기
number,push(28);
number[]; // [1, 2, 15, 4. 28]
제일 마지막 값 제거하기 ( 배열 원본을 변화시킵니다)
- number.pop();
제일 첫번째 값 제거하기 / 제일 첫번째 값 추가하기 (배열 원본을 변화시킵니다)
- number.shift(); / number.unshift(8)
객체
- 객체 선언하기(object)
var user = {
name = "byeonguk"
age = 29
weight = 80
}
name = key
byeonguk = value
var grades = {};
grades['egoing'] = 10;
grades['k8805'] = 6;
grades['sorialgi'] = 80;
배열,객체 값 사용하기/ 추가하기/ 바꾸기
Dot notation (함수에서 쓸 수 없다?)
user.name; // byeonguk
user.age;// 29
Bracket Notation
user['name']; // byeonguk
user['age'];// 29- 객체 값 추가하기
var user = {
name = "byeonguk"
age = 29
weight = 80
height = 181
}- 객체값 삭제하기
delete obj["age"]
3.추가사항
객체 속성 : object property
- 배열에 저장된 값 불러오기
function getNthElement(array, n) {
if(array, n){
return array[n]; }객체에 저장된 값 불러오기
- key 값 불러오기
for 문은 in 뒤에 따라오는 배열의 key 값을 in 앞의 변수 name에 담아서 반복문을 실행한다
for(var key in grades){
console.log(key)객체 안에 함수도 저장 될 수 있다.
- value 값 불러오기
for(var = key in grades){
console.log(grades(key))this : 함수가 가르키고 있는 객체
객체지향프로그래밍 : 서로 연관되어 있는 값과 연관되어 있는 처리를 하나의 그릇안에 모아 그룹핑 해놓은 것
배열과 객체 문제는 완전히 다르다.
서로 지정하는 것과 불러오는 것 추가하는 것 모두 다름.
객체에 배열 형식을 쓰면 안된다.
'JAVASCRIPT' 카테고리의 다른 글
| javascript 중괄호 , 대괄호, 소괄호 사용 정리 (0) | 2020.03.19 |
|---|---|
| javascript 05. ajax를 활용하여 댓글 기능 구현하기 (0) | 2020.01.16 |
| javascript 04. jquery & ajax 기본 문법 (0) | 2020.01.16 |
| javascript 03. SCOPE (0) | 2020.01.16 |
| javascript 02. 콜백함수, 객체지향 (0) | 2020.01.16 |