(회사마다 어떤 걸 SEO하고 싶은지는 다를 수 있으니 가장 기본에 충실한 것만 여기서 표현하고자 한다.)
이렇게 rendering 해줄 수 있는 templates를 하나 만들고 이제 해당 templates를 rendering 해줄 수 있는 view를 만들었다. 이것도 매우 간단하다.
classProductSeoView(View):defget(self, request, **kwargs):
product_id = int(request.GET.get('product_no', -1))
# 각자 SEO하고자 하는 코드를 적으면 된다. 아래코드는 예시로 표현하였다.
product = Product.objects.get(id=product_id)
title = product.title
description = product.description
image = product.image
url = product.url
product_info = {
'title': title,
'description': description,
'image': image,
'url': url,
}
return render(request, 'seoproduct.html', {'product_info': product_info})
(해당 코드는 예시로 적은 코드이다)
view 역시 굉장히 간단하다. 제품 번호를 받아서 거기에 맞는 제품 정보를 가지고 와서, product_info에 넣고, 해당 템플릿을 랜더링 시켜주는 것이다.
그럼 해당 view로 요청이 왔을 때 아까 위해서 만든 템플릿이 해당 product_info 정보를 받아서 랜더링 되게 된다.
이제 해당 view를 띄어줄 수 있도록 url만 하나 뚫어주면 된다. 기존 요청 오는 api아래에 seo라는 api 하나만 더 뚫어주면 된다.
# 기존 product view
re_path(r'^/product?$', ProductView.as_view(), name='product_view'),
# product seo를 위한 view
re_path(r'^seo/product?$', ProductSeoView.as_view(), name='product_seo_view'),
이렇게 되면 서버쪽은 모두 준비가 되었다.
그럼 runserver를 돌린 뒤에 해당 api로 요청을 보내보면 빈페이지가 나와 있어야 한다. 그리고 추가적으로 소스코드를 보면 meta tag에 해당 내용이 담겨 있어야 한다.
이것만 확인 되었으면 이제는 프론트 nginx의 설정을 건드려야 한다.
프론트 서버의 nginx conf파일을 변경하자. 회사마다 모두 다를 것이라고 생각하기 때문에 포인트만 잡고자 한다.
여기서 하고자 하는 것은 바로 카카오톡 봇을 파악해서, 바로 위의 SEO를 위한 서버 URL로 redirect 시키는 것이다.
프론트 서버의 nignx의 location 설정을 변경시켜주면 된다.
location /product {
# 여기는 잡고자 하는 bot의 user_agent를 모두 넣으면 된다.# 지금 여기서는 kakao talk만을 기준으로 한다.if ($http_user_agent ~* "kakaotalk-scrap") {
rewrite ^/(.*)$ [api_server_url]/seo/$1 permanent;
}
}
=> 프론트의 build된 코드를 서빙하는 것이 아니라 봇일 경우 api_server의 nginx로 seo라는 경로를 앞에 추가하여 보내도록 하였다.
이렇게 한 뒤에는 nginx -t nginx -s reload를 통해서 nignx를 다시 load시켜준다.
이제 테스트를 진행해보자!!
카카오톡에 seo를 진행하였던 링크를 복사해서 붙여 넣으면 된다. 그러면 카카오봇이 해당 사이트의 정보를 가지고 오기 위해 접근할 것이다. (혹시라도 있을 캐시를 삭제해주는 것이 좋다. 카카오 dev에서 삭제가 가능하다)
그리고 프론트 nignx의 로그를 보면
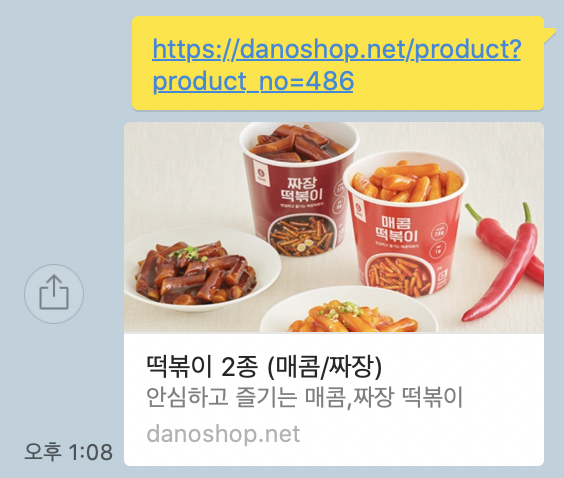
GET /product?product=486 HTTP/1.1" 301 194 "-" "facebookexternalhit/1.1; kakaotalk-scrap/1.0;
기존에 danoshop 요청 url이 seo라는 url로 붙어서 다시 들어온 것을 볼 수 있다.
그래서 그 결과는 과연 어떻게 되었을까?
기존에는
이렇게 상품을 공유해도 default 이미지가 나오던 것이 각각의 상품에 맞게 잘 나온다!!
이렇게 이쁘게 잘 되어 나온다!
이것으로 1차 목표하였던 카카오톡에 개별 링크를 공유했을 때 default meta tag가 아닌 각각의 사진과 text가 나오도록 작업을 진행하였다. 프론트 개발자분들의 리소스가 부족한 상황에서 서버 개발자인 내가 할 수 있는 부분에서 개선을 해보았다.
다만 작업을 하면서 추가적으로 고려해야 하는 부분도 발견하였다. 바로
[높은 페이지랭크를 가진 URL은 검색결과에서 더 상위에 노출 것입니다. 따라서 높은 페이지랭크를 가진 URL을 구입하여 컨텐트만 광고페이지로 이동시키는 부적절한 사례가 증가하고 있습니다. 이 때문에 구글은 302를 자주 사용하거나 부적절하게 사용할 경우 기존 사이트랭크에 상당한 패널티를 부여합니다.]
웹브라우저와 관련된 객체들의 집합을 브라우저 객체 모델(BOM: Brower Object Model)이라고 부른다. 이 브라우저 객체 모델을 이용하여 Brower와 관련된 기능들을 구성한다. DOM은 BOM 중의 하나이다. DOM은 document object model의 약자이다. 문서 객체 모델인데, 문서 객체란 <html> < body>와 같은 html문서의 태그들을 javascript가 이용할 수 있는 개체로 만드는 것. 그것을 문서 객체라고 한다.
또 뒤에 model이 붙어 있는데 여기서는 문서 객체를 인식하는 방식정도로 해석하면 좋을 것 같다.
즉 웹브라우저가 html 페이지를 인식하는 방식이다.
보통은 데이터가 변화하게 되면 양방향 바인딩으로 처리
변화(Mutation) => 특정 변화가 있으면 모델에 변화를 일으키고, view에 로직을 만들어준다. 그리고 화면에 다시 띄어준다.
페이스북에서는 다른 생각
만약에 변화가 일어나야 하면 mutation하지말고 기존에 있던 view를 날려버리고 새로 만들어버리면 어떨까? => 브라우저는 돔기반으로 작동하기 떄문에, 성능적으로 엄청난 문제가 있을 수 있다.
그래서 virtual dom이 나왔다.
가상의 돔이다.
변화가 일어나면 브라우저의 돔에 새로운 것을 넣는 것이 아니라 javascript로 이루어진 가상의 돔에 랜더링을 하고 기존의 돔과 비교를 하고 정말 비교가 필요한 부분만 업데이트 한다