그동안 서버만 하다가 회사 프로젝트로 다노 매거진을 개편하는 업무를
진행하게 되었다.
관련 글 : daeguowl.tistory.com/185
다노 매거진 개편 프로젝트를 완료하며...
올 한해 여러가지 프로젝트를 진행했지만, 정말 나의 피, 땀, 눈물이 들어간 프로젝트를 마무리하며 회고글을 적어보고자 한다. 사건의 발단 : 현재 다노에서는 매주 or 2주 단위로 1on1 이라는 것
daeguowl.tistory.com
처음 사용해보는 React로 웹을 개발하고 나니 SPA(single page application)라는 말을 듣게 되었다.
즉 한 페이지에서 각각의 컴포넌트들만 랜더링 되면서 사용된다는 것인데,
처음에는 이게 무슨 말인지도 몰랐다.
여러 페이지를 이동하는 것 같은데, 왜 싱글 페이지라고 할까...??
즉 react의 경우 build 된 이후의 파일을 보면 body 부분이
<body></body>로 텅 비어있고, js로 이 body부분을 변경해 가면서
rendering 된다는 것이다.
다만 이렇게 되면 우리의 사이트를 크롤링해가는 봇들이,
우리 사이트를 빈사이트로 인식하게 된다.
매우 큰 이슈다...
여러 부분의 단점이 있지만 일단 크게 와닿는 부분은
해당 페이지가 rendering 되기 전의 정보를 가져가다 보니,
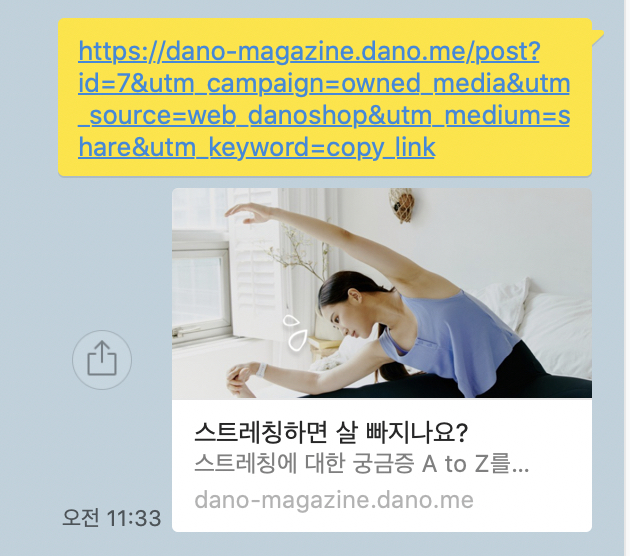
공유하기 등을 하였을 때 해당 페이지의 링크만 공유되는 불상사가 일어났다.
정말 간단하게는 대표 이미지와 description을 정해놓고 meta tag에 넣어주면 된다.
사실 이렇게만 해도 대부분의 회사에서는 해결이 될텐데, 문제는 특정 상품의 링크를 공유했을 때
해당 부분이 나왔으면 좋겠다는 것이다.(제품별로)
사실 다노샵처럼 여러 제품이 있는 경우가 아니라면
각각의 특정 페이지별로 SSR하는 것은 이미 잘 만들어진 러이브러리들이 많다.
react-helmet이라는 라이브러리인데, 이정도의 SEO가 필요하다면,
아래 글을 참고 하면 된다.
velog.io/@byseop/SPA%EC%97%90%EC%84%9C-%EC%84%9C%EB%B2%84%EC%82%AC%EC%9D%B4%EB%93%9C-%EB%A0%8C%EB%8D%94%EB%A7%81%EC%9D%84-%EA%B5%AC%EC%B6%95%ED%95%98%EC%A7%80-%EC%95%8A%EA%B3%A0-SEO-%EC%B5%9C%EC%A0%81%ED%99%94%ED%95%98%EA%B8%B0
SPA에서 서버사이드 렌더링을 구축하지 않고 SEO 최적화하기
얼마 전 create-react-app 기반의 SPA 프로젝트에서 빠른시간내에 SEO를 적용해야 하는 일이 있었습니다. 제가 아는것은 SPA의 SEO는 next.js 혹은 gatsby 를 이용하여 개발하거나, 직접 서버사이드 렌더링(Se
velog.io
아무튼 내가 하고 싶은 것은 각각의 제품별로 SEO를 진행하고 싶은 것이었다.
(일단 여기서 다룰 것은 링크를 공유했을 때 각각의 제품에 맞는 제품명과 사진을 가져가서 보여주는 것이었다.)
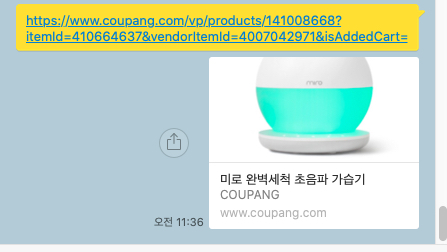
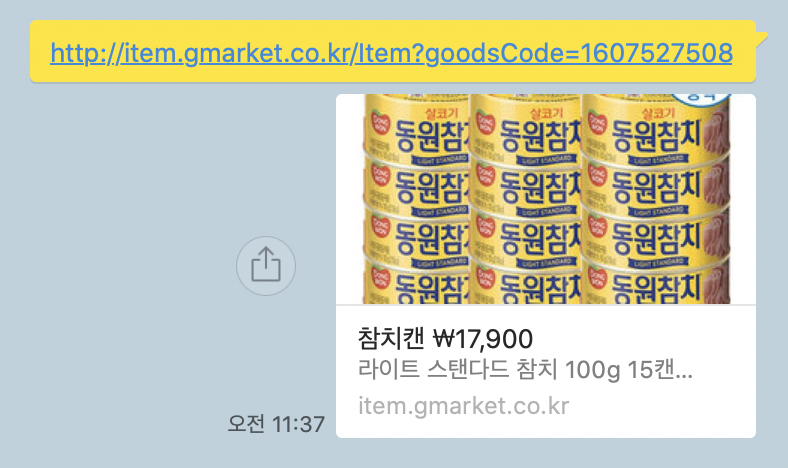
확인해보니 쿠팡과 gmarket은 잘 구현되어 있다.
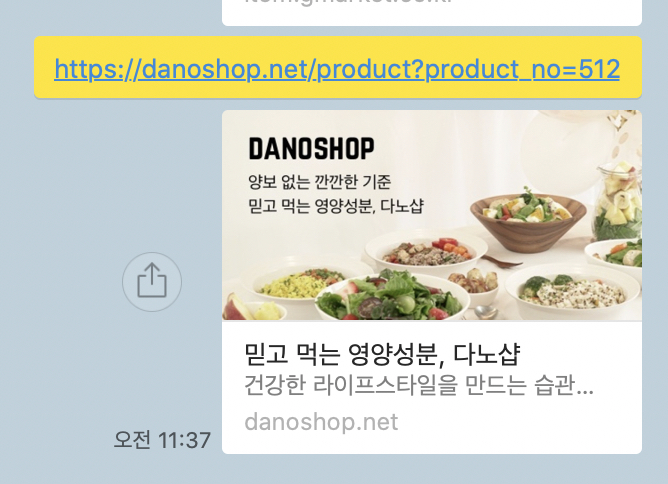
다노의 경우 위의 대표링크를 공유했을 때처럼 제품을 공유해도 SSR이 되어 있지 않아서,
default로 meta tag에 설정해놓은 이미지와 설명이 나오고 있었다.
사실 여러가지 방법들이 있겠지만,
프론트개발자분들은 너무 리소스가 없으셨고,
서버단에서 이 문제라도 해결할 수 있는 방법이 없을까 모색하였다.
일단 크롤러 봇이 프론트의 build된 코드에 접근해 버리는 순간
어떤 방법을 써도 SSR을 하는 것이 어려웠다.
그래서 프론트의 build된 코드로 접근하기 전에 붙어 있는 nginx에서
봇인지를 판단해서 우리가 만들어 놓은 페이지로 redirect를 하면 되지 않을까?라는
아이디어를 내놓게 되었다.
전체적인 그린 그림은 아래와 같다.

검정색은 일반적인 흐림이라면, 빨간색은 봇이 들어올 때의 움직임을 표현하였다.
일단 봇이 user-agent를 잡아서 봇인 경우, build된 코드로 넘기지 않고 서버의 새로운 api 로 redirect 시키는 것이다.
그리고 그 api는 서버에서 원하는 meta tag를 넣은 templates를 rendering 시켜주자고
계획을 세웠다.
이렇게 게획을 세우고 나니, 한번 해봐도 될 것 같다는 생각이 들어 바로 진행하였다.
먼저 django에 rendering 해줄 수 있는 templates를 하나 만들었다.
(현재 다노에서는 python과 django로 서버를 구성하고 있다.)
간단하게 표현하면 아래와 같다.
# product_info로 rendering할 때 data를 넘겨줄 예정
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta property="og:title" content="{{ product_info.title }}"/>
<meta property="og:image" content="{{ product_info.image }}"/>
<meta property="og:description" content="{{ product_info.description }}"/>
<title>Title</title>
</head>
<body>
</body>
</html>
(회사마다 어떤 걸 SEO하고 싶은지는 다를 수 있으니 가장 기본에 충실한 것만 여기서 표현하고자 한다.)
이렇게 rendering 해줄 수 있는 templates를 하나 만들고 이제 해당 templates를 rendering 해줄 수 있는
view를 만들었다. 이것도 매우 간단하다.
class ProductSeoView(View):
def get(self, request, **kwargs):
product_id = int(request.GET.get('product_no', -1))
# 각자 SEO하고자 하는 코드를 적으면 된다. 아래코드는 예시로 표현하였다.
product = Product.objects.get(id=product_id)
title = product.title
description = product.description
image = product.image
url = product.url
product_info = {
'title': title,
'description': description,
'image': image,
'url': url,
}
return render(request, 'seoproduct.html', {'product_info': product_info})(해당 코드는 예시로 적은 코드이다)
view 역시 굉장히 간단하다.
제품 번호를 받아서 거기에 맞는 제품 정보를 가지고 와서, product_info에 넣고, 해당 템플릿을 랜더링 시켜주는 것이다.
그럼 해당 view로 요청이 왔을 때 아까 위해서 만든 템플릿이 해당 product_info 정보를 받아서 랜더링 되게 된다.
이제 해당 view를 띄어줄 수 있도록 url만 하나 뚫어주면 된다.
기존 요청 오는 api아래에 seo라는 api 하나만 더 뚫어주면 된다.
# 기존 product view
re_path(r'^/product?$', ProductView.as_view(), name='product_view'),
# product seo를 위한 view
re_path(r'^seo/product?$', ProductSeoView.as_view(), name='product_seo_view'),
이렇게 되면 서버쪽은 모두 준비가 되었다.
그럼 runserver를 돌린 뒤에 해당 api로 요청을 보내보면 빈페이지가 나와 있어야 한다.
그리고 추가적으로 소스코드를 보면 meta tag에 해당 내용이 담겨 있어야 한다.
이것만 확인 되었으면 이제는 프론트 nginx의 설정을 건드려야 한다.
프론트 서버의 nginx conf파일을 변경하자.
회사마다 모두 다를 것이라고 생각하기 때문에 포인트만 잡고자 한다.
여기서 하고자 하는 것은 바로 카카오톡 봇을 파악해서,
바로 위의 SEO를 위한 서버 URL로 redirect 시키는 것이다.
프론트 서버의 nignx의 location 설정을 변경시켜주면 된다.
location /product {
# 여기는 잡고자 하는 bot의 user_agent를 모두 넣으면 된다.
# 지금 여기서는 kakao talk만을 기준으로 한다.
if ($http_user_agent ~* "kakaotalk-scrap") {
rewrite ^/(.*)$ [api_server_url]/seo/$1 permanent;
}
}=> 프론트의 build된 코드를 서빙하는 것이 아니라 봇일 경우 api_server의 nginx로 seo라는 경로를 앞에 추가하여
보내도록 하였다.
이렇게 한 뒤에는
nginx -t
nginx -s reload를 통해서 nignx를 다시 load시켜준다.
이제 테스트를 진행해보자!!
카카오톡에 seo를 진행하였던 링크를 복사해서 붙여 넣으면 된다.
그러면 카카오봇이 해당 사이트의 정보를 가지고 오기 위해 접근할 것이다.
(혹시라도 있을 캐시를 삭제해주는 것이 좋다. 카카오 dev에서 삭제가 가능하다)
그리고 프론트 nignx의 로그를 보면
GET /product?product=486 HTTP/1.1" 301 194 "-" "facebookexternalhit/1.1; kakaotalk-scrap/1.0;오 get요청이 왔고 301로 제대로 redirect 되었다는 표시가 나온다!
이제 서버쪽 nignx의 로그를 보면
seo/product/?product_no=526 HTTP/1.1" 200 "https://danoshop.net/product/?product_no=526 "facebookexternalhit/1.1; kakaotalk-scrap/1.0기존에 danoshop 요청 url이 seo라는 url로 붙어서 다시 들어온 것을 볼 수 있다.
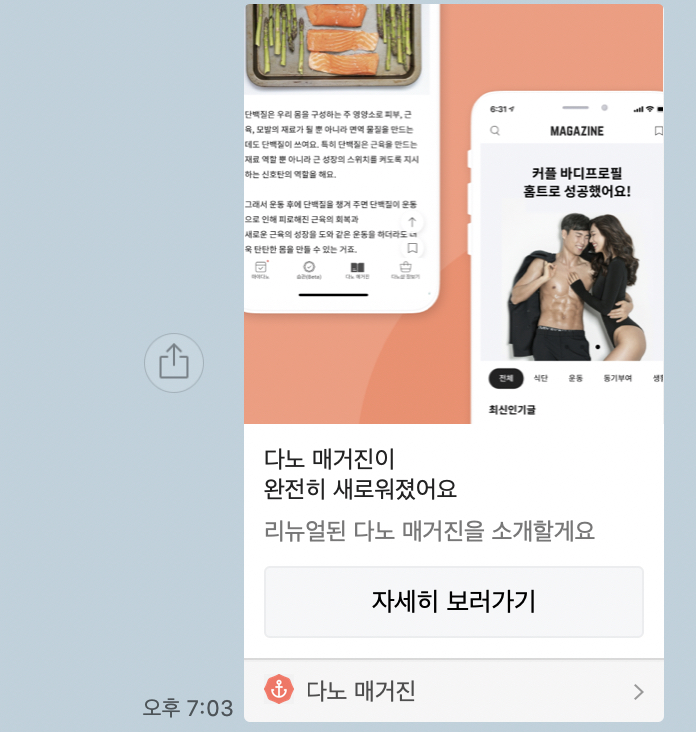
그래서 그 결과는 과연 어떻게 되었을까?
기존에는
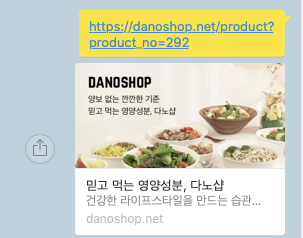
이렇게 상품을 공유해도 default 이미지가 나오던 것이
각각의 상품에 맞게 잘 나온다!!
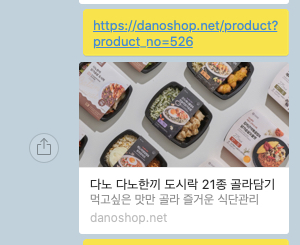
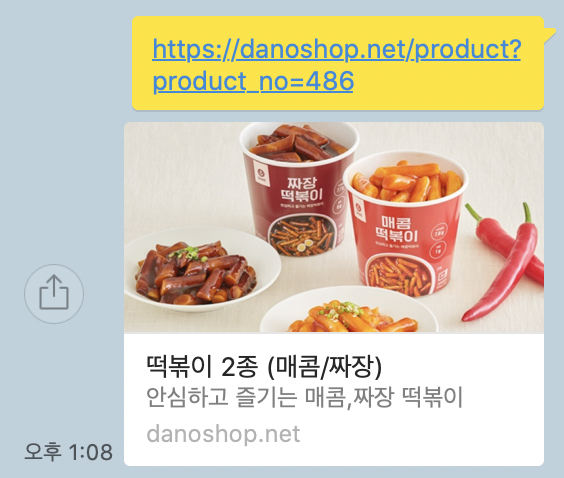
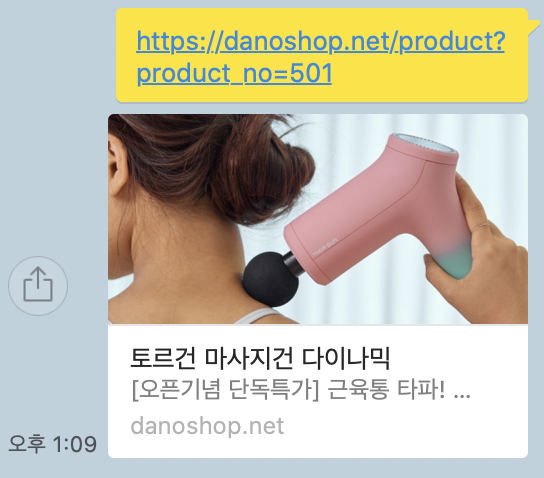
이것으로 1차 목표하였던 카카오톡에 개별 링크를 공유했을 때
default meta tag가 아닌 각각의 사진과 text가 나오도록 작업을 진행하였다.
프론트 개발자분들의 리소스가 부족한 상황에서
서버 개발자인 내가 할 수 있는 부분에서 개선을 해보았다.
다만 작업을 하면서 추가적으로 고려해야 하는 부분도 발견하였다.
바로
[높은 페이지랭크를 가진 URL은 검색결과에서 더 상위에 노출 것입니다. 따라서 높은 페이지랭크를 가진 URL을 구입하여 컨텐트만 광고페이지로 이동시키는 부적절한 사례가 증가하고 있습니다. 이 때문에 구글은 302를 자주 사용하거나 부적절하게 사용할 경우 기존 사이트랭크에 상당한 패널티를 부여합니다.]
출처: https://nsinc.tistory.com/168 [NakedStrength]
의 글이다. 봇들이 접근할 때, 302로 redirect시키는 경우 평가를 안 좋게 한다는 글도 보았다.
그리고 이미 구글봇은 js를 읽을 수 있다고 하니, 따로 해당 부분을 적용할 필요는 없어 보인다.
따라서 각자의 상황에 맞게 해결을 하면 될 것 같다.
이렇게 해결을 한 글은 없는 것 같아
누군가에게는 도움이 되었으면 하면서 글을 남긴다.
'프론트엔드' 카테고리의 다른 글
| React-Native ios StatusBar style 적용 안 될 때 (0) | 2022.02.09 |
|---|---|
| 스크롤에 따라 이미지 회전시키기 (2) | 2021.05.10 |
| react datetime 한글(년월일)로 변경하기 (1) | 2020.11.10 |
| React 웹폰트 초간단 적용하기 (0) | 2020.11.07 |
| 리액트 dom (0) | 2020.09.20 |