2019.04.09 TIL
(TIL은 스스로 이해한 것을 바탕으로 정리한 것으로 오류가 있을 수 있습니다)
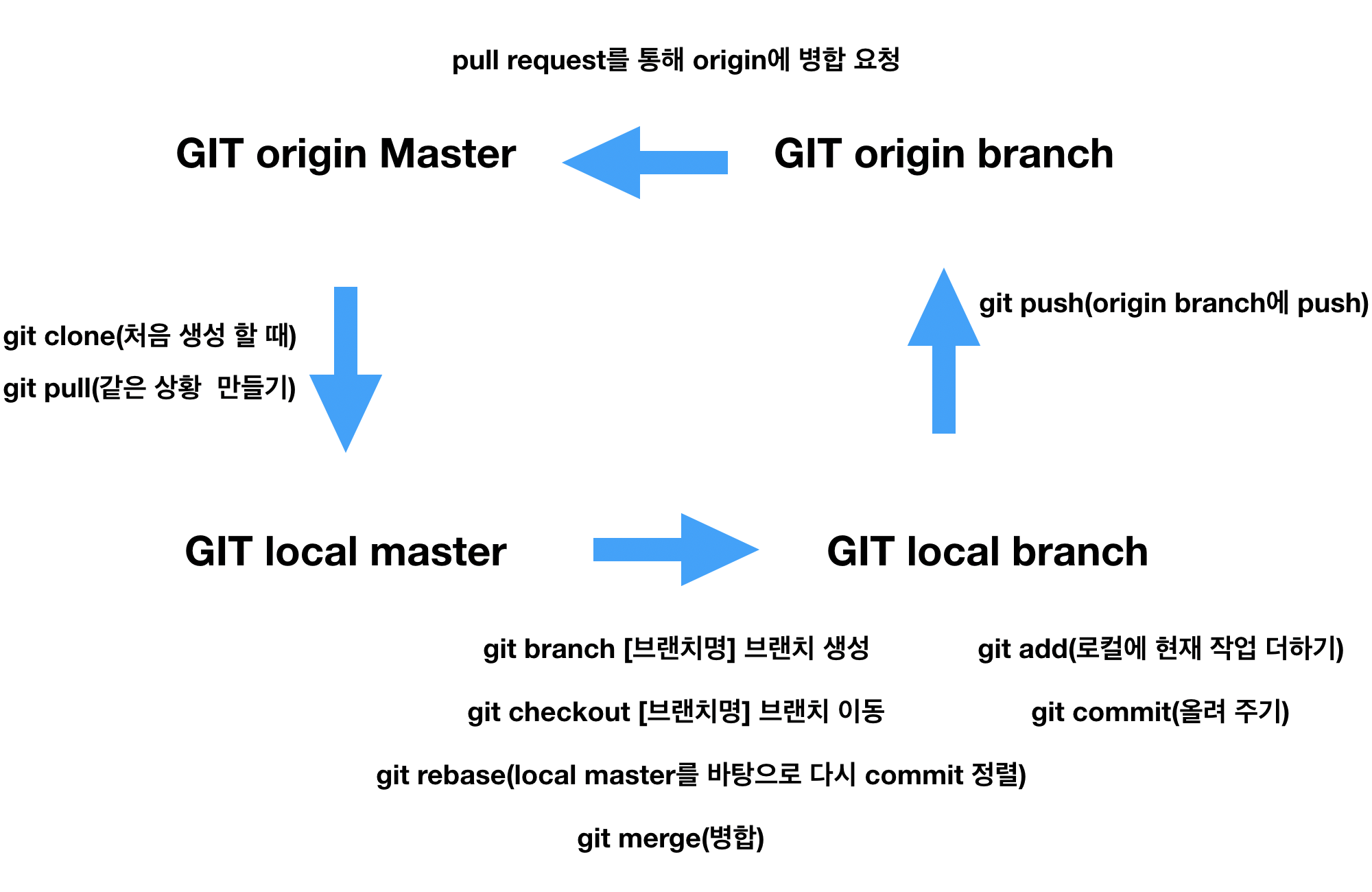
# 질문에 답하기
데이터 베이스
mysql은 관계형 데이터 베이스이다.
관계형 데이터 베이스 시스템들은 SQL 문법을 사용한다.
- nosql : 빅데이터와 같이 큰 데이터가 늘어나면서 관계형 데이터가 한계가 있다고 생각
DATABASE SERVER
server이기 때문에 앞으로 들어나지 않는다.
database server밑에서 여러개의 database가 있을 수 있고
database 밑에서는 여러개의 table이 있다.
그 안에 DATABASE가 있다.
database
- oracle이 1위 회사이다.
- 중소기업은 mysql —> php와 너무 잘 맞다. APM(apach, php, mysql)
- MariaDB
django
- postgreSQL —> open source
database는 table이라는 것을 카테고라이징 한 것이다.
- table은 entity 혹은 relation이라고 부른다.
- 열은 column 혹은 field라고 부른다.
- 행은 row 혹은 tuple이라고 부른다.(파이썬의 자료형 tuple과 동일하다)
- 또한 이 row 한 줄을 recode라고 한다.
- 레코드는 구체적인 데이터를 이야기한다.
기본적으로 행과 열을 통해서 데이터베이스에 접근한다.
DATABASE CLIENT
mysql-client
phpmyadmin
mysql query browser
navicat
- 참고사항
- utf-8 mb4 (unicode utf-8)의 의미
- a,b,c —> 1byte
- 한글 —> 3byte
- 어차피 3바이트까지 하면 되는데 굳이 4바이트까지 써야하나?
- 따라서 자체적으로 3바이트로 만들었는데
- 이모티콘이 나오면서 4바이트로 바꿈(utf-8 mb4)
시작하기
students
- student ID - int, primary key(테이블에서 오직 하나)
- height
- score
- birthday
- class ID - int, NULL
teacher
- teacher - int, primary key
- subject - varchar(가변)/ not null
- class id - int, NULL
server start
mysql.server start
mysql -u root
- mysql -u root ===> connection이 연결 TCP 연결(socket으로 연결이 둟린 것이다.)
- 이것을 session이라고 한다. TCP 연결을 했다.
- client는 여려명일 수 있다. john, greg 등
- 쓰레드의 가장 큰 문제점 : 레이스 컨디션
- 여러명이 접속하게 되면 table이 shared resource가 된다. (공유자원)
- updata문을 통해서 balance 값을 5000원에서 3000원으로 바꾸면서 끊김
- 무결점을 보장해줘야한다.
- 그렇기 때문에 session을 연 다음에 update를 하는 순간 그 쓰레드에 대해서만 복사해서 준다.
- 트랜젝션을 업데이트를 한 다음에 commit을 통해 트랜젝션을 끝내고 데이터 베이스를 바꿈.
- commit전에는 절대 데이터 베이스는 바뀌지 않는다. 무결성
- 트랜젝션과 세션의 차이를 잘 알아야 한다.
- Do it! 오라클로 배우는 데이터베이스 입문 - 이지훈 - Google 도서
유저확인
SELECT USER, HOST FROM USERS;
유저 생성 및 비밀번호 설정
CREATE USER “byeonguk”@“localhost” IDENTIFIED BY "1234";
권한 주기
GRANT ALL PRIVILEGES ON *.* TO "byeonguk"@"localhost" with grant option;
권한 적용
FLUSH privileges
권한 확인
SELECT USER, HOST, SUPER_PRIV FROM MySQL.USER;
데이터 삭제 혹은 테이블 삭제
DROP DATABASE mydb;
DROP TABLE 테이블명
테이블에 대한 정보 확인
SHOW tables
- 테이블 리스트 확인
SHOW CREATE table "테이블 명"
- 해당 테이블에 대한 정보
DESC "테이블 명";
- 해당 테이블 스키마 열람
- 스키마란 : 테이블에 적재될 데이터의 구조와 형식을 정의 하는 것
SELECT * FROM "테이블명"
- 우리가 찾던 그 정보확인
테이블 생성
CREATE TABLE students(
-> student ID INT AUTO_INCREMENT,
-> studentName VARCHAR(20) #학생의 이름이 20바이트까지 가능
-> height SMALLINT DEFAULT 200,
-> score, SMALLINT NULL,
-> birtyday DATE NOT NULL,
-> classID INT NULL,
-> PRIMARY KEY(studentID), # 오직 한개만 있다
-> FOREIGN KEY(classID), REFERENCES classes(classID)
- classID라는 외래키 참조하는데 classes 열에서 classID를 참조한다.
- 잘못되었을 때 \c를 하면 빠져나올 수 있다.
CREATE TABLE teachers (
->teacherID INT AUTO_INCREMENT NOT NULL,
->subject VARCHAR(30) UNIQUE,
->classID INT NULL,
->PRIMARY KEY(teacherID),
->CONSTRAINT fk_classID
->FOREIGN KEY (clastsID) REFERENCES classes (classID)
);
데이터 삽입
INSERT INTO students
-> (studentName, height, scores, birthday, classID)
-> VALUES
-> (‘GREG’, 180, 87, ‘2002-3-23’, 1)
칼럼(열)더하기
DESC teacher; #직관적으로 현 상황을 볼 수 있음
ALTER TABLE teachers
-> ADD COLUMN teacherName ;
SHOW CREATE TABLE teacher; #해당 테이블에 대한 정보 제공(create할 때의 정보)
백업하기
mysqldump -u root -p —databases
mydb > mydb1.sql
#mydb1.sql이 생김
카피하기
CREATE TABLE student_cp
-> (SELECT * FROM students);
SELECT * FROM student_cp #잘 복사되었는지 확인
데이터 업데이트하기
UPDATA student_cp
-> SET score = 100
-> WHERE studentName = ‘Mary’; #Mary를 해주지 않으면 전부 다 100으로
메리 점수만 확인하기
SELECT studentName, score FROM student_cp
->WHERE studentName like ‘Mary’;
# WHERE studentName like "Ma%";
# %는 어떤 글자든지 다 소화시켜준다.
데이터 베이스에 조건문 넣기 (50점 이상 70점 이하 점수 보기)
SELECT studentName, score
-> FROM student_cp
-> WHERE score > 50 and score < 70
특정 데이터 지우기
Delete from student_cp
-> WHERE studentName like “Mary’;
SELECT * FROM student_cp (확인)
foreinkey 없애기
foreinkey를 없애려면
자동으로 인덱스를 잡기 때문에
폴인키 제약조건을 없앤 다음에 쇼 인덱스를 해준 다음에 잡혀있는 인덱스를 없애준다.
1)
ALTER TABLE teachers
-> DROP FOREIGN KEY teachers;
2)
DROP INDEX classID
-> ON teachers;
SHOW CREATE TABLE teachers #확인
JOIN

join은 테이블을 가로로 연결할 때 쓴다.
- inner join
- outer join
- left outer join
- right outer join
- full outer join
- mysql, mariadb는 full outer을 지원하지 않는다.
- 필요할 때 union을 통해 구현한다.
MySQL full outer join : 네이버 블로그
INNER JOIN
ex) join 예시
student name / score / class id / teacher name / subject
==> class id로 묶는다.( class id에 대한 교집합)
NULL을 어떻게 처리할 것인가?
if select studentname, classid, teacher 이렇게 하면 classid가 누구것인지 알수가 없다.
S.를 붙여 student 표현 T.를 붙여 teacher 을 표현
- 적용 방법
- SELECT S.studentsName,S.score, S.classID, T.teacherName, T.subject
- FROM students S INNER JOIN teachers T (student가 left teacher가 right)
- ON S.classID = T.classID
- ORDER BY S.classID
LEFT OUTER JOIN ( 왼쪽에 위치한 집합은 다 나온다.)
SELECT S.studentName, S.score, S.classID,
-> T.teacherName, T.subject
-> FROM students S LEFT OUTER JOIN teachers T
-> ON S.classID = T.classID
RIGHT OUTER JOIN (오른쪽에 위치한 집합은 다 나온다.)
SELECT S.studentName, S.score, S.classID
-> T.teacherName, T.subject
-> FROM students S RIGHT OUTER JOIN teachers T
-> ON S.classID = T.classID;
FULL OUTER JOIN
SELECT S.studentName, S.score, S.classID
-> T.teacherName, T.subject
-> FROM students S LEFT OUTER JOIN teachers T
-> ON S.classID = T.classID
-> UNION
-> SELECT S.studentName, S.score, S.classID
-> T.teacherName, T.subject
-> FROM students S RIGHT OUTER JOIN teachers T
-> ON S.classID = T.classID;
GROUP BY
- 전체 평균
- SELECT AVG(score) FROM students;
- 반별로 평균을 알고 싶다.
- SELECT classID, AVG(score)
- -> FROM students
- -> GROUP BY classID
- 만약에 반 배정 안 받는 애들은 빼고 싶다.
- SELECT classID, AVG(score)
- -> FROM students
- -> WHERE classID IS NOT NULL
- -> GROUP BY classID;
- 평균 65점 이상인 반을 본다.
- SELECT classID, AVG(score)
- -> FROM students
- -> WHERE classID IS NOT NULL
- -> GROUP BY classID
- -> HAVING AVG(scores) > 65;
WHERE 와 GROUP BY, HAVING
WHERE와 ==> 그룹을 하기 전에 조건절 수행
GROUP BY
HAVING의 차이 ==> 이미 그룹바이로 그룹이 끝난 이후에 조건절 수행(반듯이 그룹을 한 것에 대해서만 조건절을 수행한다)
M : N
CREATE TABLE subjects(
-> subjectName CHAR(20) UNIQUE NOT NULL, #unique not null은 프라이머리 key가 없으면 생성한다.
-> roomNum TINYINT NOT NULL);
INSERT INTO subjects
(subjectName, roomNum)
VALUES ('math', 101), ('literature', 105),
('science', 107), ('english', 110), ('ethics', 111);
학생 입장에서 subject name + 강의실 번호까지
sql> SELECT ST.studentName, ST.score,
SB.subjectName, SB.roomNum
FROM students ST INNER JOIN student_subject SS
ON ST.studentName=SS.studentName
INNER JOIN subjects SB
ON SS.subjectName=SB.subjectName
ORDER BY ST.studentName;
과목 입장에서 배열
sql> SELECT SB.subjectName, SB.roomNum,
ST.studentName, ST.score
FROM students ST INNER JOIN student_subject SS
ON ST.studentName=SS.studentName
INNER JOIN subjects SB
ON SS.subjectName=SB.subjectName
ORDER BY SB.subjectName;
SELECT의 순서가 바뀌는 것은 크게 의미가 없고
마지막에 ORDER BY에 따라서 정렬 순서를 정해준다.
SQL
- VIEW
- INDEX
- CLUSTERED INDEX
- SECONDARY INDEX
VIEW
VIEW는 select문이다.
view를 마치 테이블처럼 사용한다.
- view는 select문일 뿐이지 테이블이 새로 만들어지는 것이 아니다.
- 가독성이 높아진다.
- 보안문제 해결
ex) 쇼핑몰
customer / 생년 월일 /
- 알바생에서 customer 테이블을 그대로 보여주면 안되니깐 view(생년월일이 없는)를 하나 만들고 권한을 부여(GRANT)
CREATE VIEW
CREATE VIEW view_st_sb_join
AS
SELECT ST.studentName, ST.score,
SB.subjectName, SB.roomNum
FROM students ST INNER JOIN student_subject SS
ON ST.studentName=SS.studentName
INNER JOIN subjects SB
ON SS.subjectName=SB.subjectName
ORDER BY ST.studentName;
WHERE 적용 가능
SELECT * FROM view_st_sb_join;
sql> SELECT * FROM view_st_sb_join
WHERE score BETWEEN 50 AND 70;
DROP VIEW 적용 가능
DROP VIEW view_st_sb_join;
INDEX
index를 쓰는 이유 <-- 데이터 검색
Tree BST --> o(log n)
단점 보완 -> red - black - tree (균형 이진 트리) 추가 단점 보완 => B-tree
CLUSTERED INDEX
- 한 테이블마다 1개씩만 존재한다.
- 데이터 자체를 클러스트 인덱스에 맞추어서 정렬한다.
- primary key가 클러스트 인덱스가 된다.
- primary key를 안 잡고 데이터를 넣은 뒤 primary key를 잡으면 나중에 굉장히 정렬하는 시간이 오래 걸릴 수 있다. ==> 항상 미리 잡고 시작하자.
SECONDARY INDEX
- 원하는만큼 붙일 수 있다.
- B-트리라는 자료구조를 만들고 실제 데이터를 참조해서 만든다.
- where 에 쓰인다. ex) where classID = 3
- secondary index를 언제만드냐?
- where가 자주 쓰일 때 만들어 놓으면 search를 할 때 secondary index를 활용하여 서치
- 쓰는 이유 : 검색 속도가 엄청나게 빨라진다.
- 단점 : 테이블에 대해 insert를 계속하고 업데이트를 계속한다고 하면 계속 B-tree도 업데이트 시켜줘야하고, 수정, 삽입 등이 많이 늘어나면 페이지 분할이 일어나서 속도가 늦어질 수 있다.
- where을 내가 얼마나 쓸 것인지 파악하고, 내가 수정 삽입 등을 얼마나 할 것인지 고민
- CREATE INDEX는 secondary index만 만들 수 있다.
- cluster int를 만들기 위해서는 ALTER TABLE이라는 커맨드를 써야한다.
참고사항
내부 스키마 외부 스키마 개념 스키마
[DB기초] 스키마란 무엇인가?