주니어 개발자의 새벽배송 개발기
커머스는 우리가 생각하는 것보다 훨씬 더 복잡하다.
단순히 상품을 진열하고 구매하는 것을 벗어나서, 실제 구매가 이루어진 후의
상품 출고 과정과 고객분들의 후기, 그리고 교환과 반품과 같은 CX처리까지...
이 모든 과정이 끝나야지 정말로 커머스의 한 사이클을 돌았다고 이야기할 수 있다.
물론 사람이 진열할 상품을 고르고, 가격을 설정하고, 상품을 보내고, CX상담을 하고 하지만
이 모든 것들을 가능하게 하는 로직이 바탕이 되어야 한다. 발생할 수 있는 모든 케이스에 대해서 로직 처리가 되어있다 보니
커머스의 서버는 방대해질 수밖에 없다.
다노에 입사한 지 어느덧 2년이라는 시간이 지났다. 그 과정 속에서 나는 더 성장을 한 것인지, 정체되어 있었는지 잘 모르겠다.
가끔은 잘하고 있다는 생각이 들 때도 있었고, 또 어쩔 때는 다른 개발자들과 비교하며 정체되어 있다는 느낌을 받기도 했다.
뭐 이유야 어찌 되었든 나는 필요에 의해 개발을 하고 있는 사람이고, 개발 그 자체를 즐기진 못하고 있다.(물론 내가 개발을 못 한다는 이야기는 아니다.)
개발이 정말 나의 적성에 딱 맞으면 좋겠지만, 애당초 잘 맞지 않을 것이라는 것을 예상하고 들어왔고,
나름 내가 개발자로서 목표하였던 것들을 성취하면서 성장해 나가고 있는 것 같다.
어느덧 2년 넘게 바라보았던 다노샵 서버에 이제는 너무 큰 애정이 생겨버렸다.
수 없이 마주 하였던 버그들을 수정하고, 수많은 신규 피처들을 붙이면서 다노샵은 점점 고도화되어 가고 있다.
처음 다노샵은 카페 24에서 시작하였었다.
그러다가 카페 24에서 자체에서 운영하는 독립몰로 옮기기 위해 정말 노력하셨던 분들이 있었고,
나는 그 옮겨놓은 독립몰 큰 틀 안에서 새로운 것들을 지속해서 만들어 나갔다.
아무튼 처음 입사 때부터 사수분과 둘이서 다노샵 서버 전체를 다 보았고 유지보수 및 피처개발을 해나갔다.
(이런 경험은 쉽게 쌓을 수 없다고 생각한다. 정말 감사하다고 느낀다.)
큰 이슈가 없으면 기존 것을 최대한 활용하고 발전시켜 새로운 기능들을 붙여나갔다.
(지금 다노샵 독립몰은 정말 정말 다양한 기능들이 추가되어있다. 이게 카페 24 혹은 고도몰을 활용하지 않고 독립몰을 활용하는 이유이기도 할 것이다.)
새벽배송 관련 서비스 오픈은 작년부터 SCM팀에서 진행하고 싶었던 일이기도 하였고, 다노샵을 이용하는 나라는 고객 입장에서도 너무나도 도입되면 좋겠다고 생각한 배송 서비스였지만 여러 가지 회사 사정들과 급한 이슈들로 인해 뒤로 미뤄져 갔다.
아무튼 시간이 흘러 다노샵도 새벽배송을 도입하기로 결정이 되었고,
해당 피처 작업을 맡아서 진행한 스토리를 좀 적어보려고 한다.
새벽배송? 일단 무엇을 해야 할까? 너무나도 막막한 부분이지만,
SCM팀의 리더분의 이야기는 심플했다.
"이미 배송 협력사에서 시스템이 다 갖추어져 있어서 저희는 기존에 나오던 금일 출고될 상품들의 엑셀 파일에서
새벽배송 관련된 row만 한 줄 추가되면 됩니다."
이것을 믿고, 새벽배송 TF팀은 희망을 가졌다.(서버1, 프론트1, 디자이너1, PM1, QA1)
"그래. 새벽배송이 가능한 고객분들에게는 주소랑 연락처 이외에 새벽배송 관련된 정보를 더 받자. 그리고 그걸 서버 쪽에서 핸들링해서 출고 파일 뽑을 때 추가해주자"
오 ...!! 쏘 심플하다!!! 정말 저거면 된다고?! 생각하며 시작한 새벽배송은
DUE 자체도 1달 정도로 길지 않았다.
그렇게 출사표를 던졌다.(이때까지만 하더라도 거이 새벽배송은 서버 쪽만 건들면 되는 거 아닌가 라는 내부적인 생각도 있었다. 우리 TF팀조차도..)

(다노는 정말 응원도 많이 해준다 ㅎㅎ)
하지만 과연 그랬을까....??? 일단 가장 큰 문제는 현재 다노샵에서는 현재 주문서에서 주소지를 받고 변경할 수 있는 구조인데, 그렇다면 만약에 고객이 새벽배송만 가능한 상품을 가지고 주문서로 간 뒤, 새벽배송 불가능 주소지를 입력하게 되면 그 주문서에서 "이 상품은 새벽배송만 가능한 상품입니다"와 같은 알람이 뜬 뒤에 주문서를 탈주해야 하는 시나리오였다.
결국 고객 경험에서 매우 좋지 못한 FLOW였고 이것을 위해 최소한 장바구니 단계에서 혹은 제품 상세페이지 단계에서 주소지를 넣도록 하기 위한 조치가 필요했다. (그 이유 때문이었는지 새벽배송을 하는 다른 업체들을 참고해보아도 모두 그렇게 하고 있었다.)
결국 그러기 위해서는, 주문서, 장바구니 쪽 모두 대대적인 손을 봐야 하는 상황에 직면하였다. 뿐만 아니라 제품 상세 페이지에서도 새벽배송이 가능한지 여부등을 정확히 안내해야 될 필요성이 있었고 이것은 나의 주문 목록에서도 마찬가지였다. 그리고 추가적으로 중요한 것은 새벽배송이 도입되게 되면서 기존에 택배로만 가던 우리 배송 체계가 변경되고, 새벽배송지인지 혹은 일반 택배 배송지인지에 따라서 출고 날짜가 다를 수 있다는 것이었다.... (주문 마감시간부터 택배사 휴일, 출고 가능 날짜까지 모두 다르다)
WOW..... 기존에 출고 예정일을 안내해주는 로직 역시 매우 복잡한 상태였는데 이제는 이것을 새벽배송까지 추가하여 정확히 안내해야 한다는 것이 쉽지 않았다. 또한 제일 큰 문제는 ... 고객들에게 일괄적으로 안내되는 출고일과 실제 출고일이 전혀 다를 수 있는 것이었다.
기존에 CX에서 나왔던 이슈 중에 한 가지는
고객님은 제품 상세페이지에서 분명 이 날짜에 배송이 된다고 하여서 구매를 하였는데 실제로는 그렇지 못했다는 것이다.
하지만 이 부분은 해당 시기에 고객님께 어떻게 안내되었는지 알아내기가 쉽지 않았고, CX처리 역시 쉽지 않았다.
그나마 매일매일 SCM팀이 출고작업을 진행해주었기 때문에 그동안 큰 이슈가 없었지만 (아무튼 다 출고가 되니),
고객에게 언제로 안내되었고 정확히 언제 출고가 되었는지는 새벽배송을 기점으로 더 중요한 이슈가 되었다.
상세페이지에서는 주소지 상관없이 특정 로직을 따라서 출고 예정일을 안내해주고 있었고, 그 대신 매일 돌아가는 출고 작업 로직 속에는 전체 상품을 가지고 와서 '이 제품은 제주도 배송지라서 제외시켜야 해 혹은 이 등록된 주소지는 주말 수령이 불가능하니깐 제외하자. 오늘 이 상품은 배치 가능 요일이 아니야 등"을 체크하면서 출고 작업의 속도는 나날이 늦어지고 있었다.
그렇기에 상세에서 고객에게 안내되는 출고 예정일은 정확할 수가 없었고(정확하지 않으면 1~2일 과 같이 애매한 표현을 쓰게 된다.) 이것은 새벽배송이 도입되면서 더욱 복잡하게 될 예정이었다. 고객에게 안내되는 출고일자가 언제였는지 알 수 없기에 배송이 늦어진다 하더라도 CX처리는 불가능했고, 실제 우리 출고가 얼마나 정확하게 이루어지고 있는지 측정될 수도 없었다.
아무튼 다노샵 서버를 개발하고 있는 개발자로서, 이번 새벽배송은 선택의 기로에 선 것과 같았다. 사실 어찌 되었든 고객이 마주하는 결과물은 비슷할 것이기에, 기존의 것에 추가하여서 갈 것인지 아니면 새롭게 판을 만들지...
사실 기존의 것에 추가하여서 가도 기존의 출고 예정일을 뽑는 로직이 더 복잡해지고, 고객에게 안내가 정확히 안 나가고, 기존 배치작업도 더 시간이 오래 걸리고 그것밖에 없지만.....(내 몸도 편할 수 있다!!)
앞으로 다노는 10배 더 성장할 수 있다고 생각하고, 그렇다고 하면 지금이 결정을 내려야 하는 시기가 아닌가라는 생각이 들었다.
그렇게 나는 목표를 좀 다르게 잡았다. (목표를 보면 알겠지만 새벽배송에 대한 목표가 없다.)

위와 같이 7가지의 objective를 세웠고
아래와 같이 좀 더 구체적으로 하위 목표들을 세웠다.
위를 정확하게 달성하면 새벽배송과 같은 다양한 케이스도 충분히 처리할 수 있었다.
구체적 KR
- 출고 작업 간소화
기존에 여러 개로 나뉘어서 관리되던 출고 작업을 한 군데로 모으는 작업.(출고배치, 출고배치그룹, 오전출고 등등)
상황에 따른 출고 작업 (특정 상품 제외, 특정 상품만 선택, 제품별 마감시간 적용, 강제 주문 마감시간 설정, 주문 파일만 생성) - 출고 작업 속도 10배 개선
평소 1시간(오전 오후 출고 모두) 정도 소요되던 출고 배송 관련된 배치작업 ⇒ 5분 이내로 개선(10배는 오버인가...) - 고객에게 명확한 배송일자 안내
상세페이지 배송 관련된 안내 및 주문서 페이지 배송 관련 안내, 출고 작업, 마이페이지 모두 배송 관련 통일 - 출고 예정일과 실제 출고일 간의 간극 파악 및 트레킹
위에서 통일된 고객에게 안내되는 출고 예정일과 실제 출고일 간의 간극 파악
매일 마다 슬랙 알림을 추가하여 불편 받는 고객이 없도록 트레킹 - 출고 예정일이 늦어진 고객에 대한 CX처리 간소화
출고 예정일이 늦어진 고객에 대한 알림톡 혹은 일괄 문자 전송 기능 추가
주소지 변경 기능 ⇒ 고객이 직접 할 수 있으면 CX를 훨씬 줄일 수 있을 것 같다.(상품 준비 중 단계) - SCM팀에서의 업무 효율성 극대화
매일 출고될 수량에 대한 파악 admin
배송이 늦어지는 상품에 대한 핸들링 (특정 제품 제외 후 출고 진행 / 특정 제품만 출고 진행)
배송 준비 중 ⇒ 배송 보류 일괄 처리 등
출고 마감 일시에 대한 핸들링
다양한 출고 케이스 핸들링(수량으로 출고 등) - 2주간 사고 0건
하나하나의 objective가 중요했고 꼭 달성해야 하는 목적들이라고 생각했다.
나의 머릿속에 떠나지 않았던 keyword는
"고객에게 명확하게 출고일에 대해서 안내하고, 그 출고일을 저장해놓고, 그 출고일자에 배치작업이 이루어지면 된다." 였다.
즉 이것을 위해서
- 먼저 고객의 주소지에 따라서 명확하게 출고일자가 안내되어야 하며
- 구매할 당시에 해당 출고일자를 저장해놓고
- 출고 배치는 오늘 날짜에 돌아야 하는 것들만 뽑아서 돌린다.
이렇게 되면 기존에 전체 상품을 대상으로 돌아가던 출고 배치가 더 이상 그럴 필요 없이 오늘 돌아가기로 한 주문건들만
그대로 돌려버리면 되니 속도도 충분히 개선될 수 있을 것 같았다.
아무튼 새벽배송 때문에 시작하게 되었지만, 다노샵 전반적인 출고 관련된 로직을 다 변경하는 작업을 하게 되었다.
그중에서 제일 중요한 로직은 바로
- 고객의 주소지에 따라서 명확하게 출고일자를 안내되어야 한다 였다.
이것은 상품은 배송하는 업체마다, 혹은 상품에서 새벽인지 일반인지 그리고 휴일 정보 혹은 주문제작 상품, 제주 배송 건인지에 따라서 여러 가지 케이스로 나뉠 수 있었다.
새벽배송이 추가되면서 기존 출고 FLOW가 전체적으로 어떻게 변경되는지 확인해야 했고, 정확한 출고일을 계산하기 위해서 정말 중요한 것은 SCM팀과의 정확한 소통이었다. 나 혼자만의 생각으로 "이 날짜에 출고되어야 해"라고 짠 것이 SCM팀에서 보기에는 전혀 다를 수 있었고, SCM팀에서 바라는 니즈를 명확하게 파악하고, 정확한 출고일이 맞는지 뽑아내는 커뮤니케이션이 정말 중요했다.
그렇기에 새벽배송을 시작하고 제일 먼저 한 것은 SCM팀과의 회의였다.


그게 정말 힘든 일이기도 하였는데, 그래도 2년 동안 다노샵의 전반적인 로직부터 SCM팀과의 협업의 경험들이 그저 시간을 보냈던 것만은 아니었나 보다. 서로 무슨 이야기를 하는지 정확하게 파악할 수 있다는 것부터가 정말 감사했다.
어떤 것들을 고려해야 하는지, 또 기존에 이미 짜여진 로직들을 어떻게 통합시킬 수 있을지 고민하고, 복잡한 것들을 단순화시키는 과정까지 전체적인 설계를 하는 일은 분명 쉽지 않았지만, 2년 동안 다노샵만을 했었기에 충분히 챌린지 할만했다.
다노샵 현재 모습에서 새벽배송을 추가하는 작업은 정말 그 누구가 와도 나보다 잘할 수는 없다고 자부심을 가졌다.
그리고 그것을 믿고 신뢰해주는 리더와 팀도 있었다.
제품 단위에서 새벽배송이 가능한지 혹은 새벽배송만 가능한지 등을 핸들링하고
각각의 상황에 맞게 출고 형태를 설정할 수 있도록 하였다.
기존에 흩어져 있던 출고 관련된 정보들을 모두 통합하여 새로운 형태의 출고 배치 통합관리를 신설하고, 거기에는 발송업체부터
출고 형태, 주문 마감시간, 배송 휴일, 배치 가능 요일 등을 설정할 수 있도록 하였다.
그렇게 상품 단위로 기본 배송, 새벽 배송으로 나누어서 출고 관련된 정보들을 엮어 놓고,
이것을 바탕으로 정확한 출고 배치 일과 출고 예정일을 뽑는 로직을 구현하였다.
(출고 배치일은 우리가 출고되어야 하는 엑셀 파일을 만들어서 업체에 넘기는 시점이고, 출고 예정일은 해당 업체에서 출고가 되는 시점이다.
때에 따라서 주문 제작 상품의 경우 다를 수 있다.)
다양한 케이스를 고려해야 했기에 이 로직을 잘 짜는 것이 정말 중요했고, 이 로직을 통해서, 제품 상세부터 장바구니, 주문서, 추후 출고까지 모두 관여하는 메인 로직이었다. 결국 로직이라는 것을 잘 짜기 위해서는 이것을 말로 풀어쓸 수 있어야 한다.
정말 이 로직을 짜기 위해서 화이트보드를 몇 번이나 지우고 새로 그리고 했는지 모르겠다.
분명 '오! 모든 케이스를 다 커버했다' 하고 나왔던 Flow도 갑자기 예외가 나오면서 수정해야 되는 경우가 다반사였다.

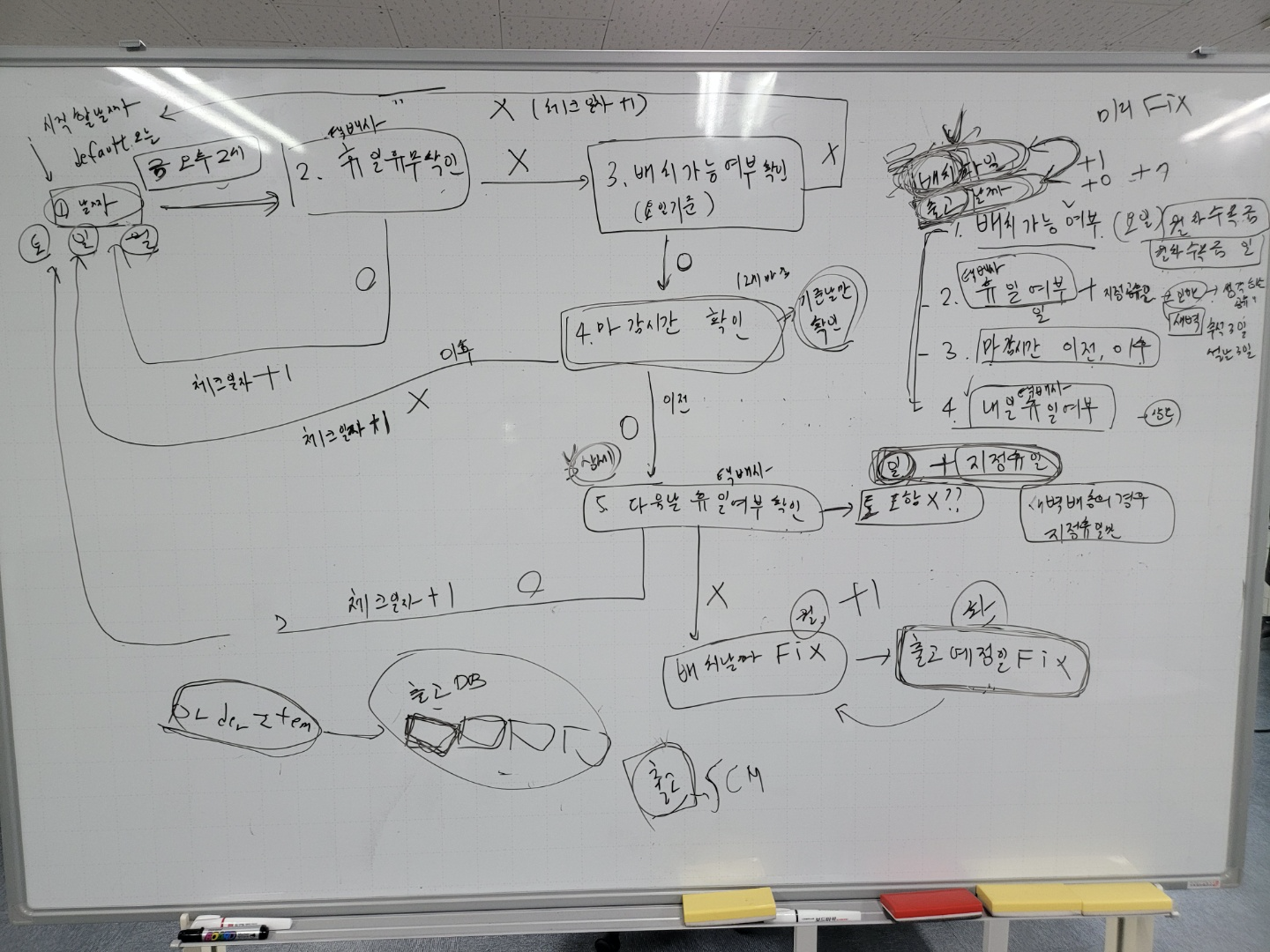

메인 로직은 아래와 같다.
1. 체크할 날짜를 넣는다.(오늘부터 시작)
2. 택배사 휴일인지 파악한다. (택배사 휴일은 새벽, 일반, 업체 발송에 따라 다르다.)
=> 휴일인 경우 하루를 추가하여 1번부터 다시 시작한다.
3. 오늘이 배치 가능한 요일인지 파악한다.
=> 배치 가능 요일은 배송 형태 혹은 제주 산간 , 주말 수령 가능 여부에 따라서 달라질 수 있다.
=> 불가할 경우 하루를 추가하여 1번부터 다시 시작
4. 체크하는 날짜가 오늘이면 주문 마감 시간을 확인한다.
=> 주문 마감 시간이 지났으면 하루를 추가하여 1번으로 시작한다.
5. 배치 날짜와 출고일을 1차 FIX 하고 일반과 주문 제작 상품에 따라서 다르게 핸들링 처리한다.
- 이미 제작이 되어있는 일반 상품의 경우 출고 익일날 휴일인지 확인하고 그렇다면 1번부터 다시 시작
- 주문 제작 상품의 경우 배치 날짜는 FIX하고 출고 예정일을 대상으로 익일날 휴일인지 확인하며 출고예정일을 조정
6. 최종 배치 예정일과 출고 예정일 FIX
정말 간단해 보이는 이 로직을 만들기 위해 다양한 케이스들을 만들어서 테스트하고, 수정하고를 수없이 반복했다. 물론 이 로직도 완벽하지 않을 수 있고, 어떤 케이스가 또 생기느냐에 따라서 수정해야 할 수도 있지만 아무튼 이제는 다노샵의 출고 관련된 안내 및 실제 출고 작업은 모두 이 로직으로 통합되었다.
물론 여기서 끝이 아니었다.
이 로직을 바탕으로 세트 상품들은 어떻게 출고 작업을 진행할지 SCM팀과 논의하여, 하위 구성품들의 출고일을 바탕으로 새롭게 출고일을 계산하는 로직을 추가하고, 특정 케이스(장기간 휴무일이 있거나, 택배사 이슈 등)에 따라서 더 상위에서 핸들링할 수 있는 케이스들을 추가해주었다.
그리고 이 로직을 바탕으로 다노샵의 메인 로직들을 수정하였다. 제품의 상세페이지에서는 고객의 주소지를 모르니깐 일반적인 출고 예정일을 안내하며, 실제 고객이 장바구니에서 주소지를 입력하는 순간부터는 정말 정확한 출고일을 안내하여, 주문이 완료될 때는 그 안내된 출고 관련된 정보를 DB에 저장하였다.(물론 가상 계좌입금에 대해서는 실제 입금되는 시점에 또 핸들링되어야 했다...)
그렇게 되고 나니 정말 좋은 점은, 일단 우리가 오늘 보내야 하는 배치작업 및 출고 작업에 대해서 미리 파악하고,
핸들링할 수 있는 것이었다.

결국 생각만 하던 실제 우리 다노에서 얼마나 출고를 잘 관리하고 있는지, 오차 없이 출고되는지 확인할 수 있게 되었고,
이때 따라서 CX처리도 훨씬 정확하게 처리할 수 있게 되었다.
그리고 무엇보다 중요한 출고배치작업!!
과연 10배 성능 향상은 가능했을까??
평소 한 번 전체 주문건들을 대상으로 돌면 20분 ~ 30분 걸리던 작업은 ...
무려 1분 안에 끝나게 되었다!!!!!!!!!!!!!!!!!!!

기존에 출고 배치 작업에서 체크하던 부분들을 전혀 체크해줄 필요가 없어졌기에 속도가 훨씬 더 향상될 수 있었다.
아무튼 기대한 것 이상이었다.
또한 다양한 케이스에 맞추어서 출고 배치 작업을 핸들링할 수 있도록 하였다.
특정 상품들만 출고를 진행한다던지, 특정 상품을 제외하고 출고를 진행할 수도 있고,
주문 마감 시간을 임의로 설정한다던지, 혹은 특정 수량만큼만 출고를 진행하고 싶다던지
그냥 출고 파일만 뽑아본다던지 등등
SCM팀에서 이야기한 다양한 요구 조건에 따라서 출고 배치를 등록할 수 있도록 하였다.
그렇게 위에서 이야기했던 Objective 중 몇 가지를 달성했을까?
1번 달성!
2번 달성!
3번 달성!
4번 달성!
5번 달성!
6번 달성!
7번은 달성을 위해 출고 작업이 많이 변경되는 만큼 서버 쪽 먼저 라이브 하여, 실제 SCM팀에서 테스트를 진행해주고 계시고 있고
아직 프런트 쪽이 라이브 전이라 더 파악해봐야 하지만, 테스트하면서 이슈들을 미리 잡고 있기에 달성할 수 있다고 믿고 있다...!!
새벽 배송과 관련된 작업이었지만,
목적을 새벽 배송에 두지 않았고, 다노샵 전반적인 출고 관련된 작업을 개선하기 위해
목적을 잡았던 것은 정말 신의 한 수였다.
생각보다 스쿱도 커지면서 실제 고객 라이브 일정이 조금 밀리긴 했지만 아무튼 온전히 한 달 이상 이 작업만을 생각하면서
몰입할 수 있었던 시기인 거 같다.
사실 사수분이 퇴사하시고 이런 큰 작업을 혼자서 진행하면서 압박도 많이 받았다. 이제는 정말 내가 실수해도 뒤에서
봐줄 수 있는 사람이 없었기에 더더욱 실수하지 않도록 신경 써서 개발하여야 하였다.
그리고 막상 라이브하고 나니 허무하기도 했다. 정말 많은 부분 개선하였지만,
실제로 성능이 개선되었을 것을 느끼는 사람은 매일매일 출고 작업을 진행하는 SCM팀이 전부였고,
내가 이것을 위해서 얼마나 많은 고민을 하고 노력했는지 공감해줄 수 있는 사람이 부재하는 것은 생각보다
크게 다가왔다.(실제로 공감하기 위해서는 비슷한 이해도를 가진 사람이 있어야 하는 것 같다.)
누군가에게 인정이나 칭찬을 바라고 했던 작업은 아니었지만,
사수분이 계셨다면, 분명 내가 했던 작업들에 대해서 진심으로 공감하고, 얼마나 노력을 해주었는지
알아주셨을 텐데... 뭔가 지금 내가 했던 작업을 얼마나 노력했는지 알아줄 수 있는 사람이 없고,
나도 언젠가 다노를 떠나게 되면 이건 그냥 나의 기억 속에서만 존재하겠지라고 생각하니 허무하기도 하였다.
아무튼, 다른 사람들이 몰라 준다고 해도,
내가 알고 있고, 정말 열심히 했다.
이 글은 무언가,
스스로에게 수고했다고 적어놓는 글이다.
새벽남 이제 bye bye!

PS. 그리고 항상 개발의 마지막은 고객 반응이다...

'프로젝트' 카테고리의 다른 글
| 2년의 시간과 5000만원을 잃고 배운 것들 (6) | 2022.08.10 |
|---|---|
| 다노 매거진 개편 프로젝트를 완료하며... (0) | 2020.11.29 |
| 메모리즈 프로젝트 ver0.1 (1) | 2020.04.29 |
| 개발일지 -2 (0) | 2020.04.13 |
| 메모리즈 프로젝트 (0) | 2020.04.08 |