- 해당 정리는 pycon 2015 celery 강의 자료와 pycon 2019 celery 강의자료를 바탕으로 만들었습니다.
아래의 2개의 영상은 celery를 이해하는데 매우 좋습니다. 꼭 보시기를 추천드립니다!
- 참고:
정민영: Celery의 빛과 그림자 - PyCon Korea 2015 - YouTube](https://www.youtube.com/watch?v=3C8gBRhtkHk)
셀러리 핵심과 커스터마이제이션 - 이지훈 - PyCon.KR 2019 - YouTube](https://www.youtube.com/watch?v=vGPyjJ1jWUs)
Celery
-
Distributed task queue 혹은 종합적인 비동기 처리기

비동기 처리기?
-
비동기 처리기는 동기적으로 수행하지 않아도 되는 일들을 처리해주는 역할
-
결과를 즉시 받을 필요가 없거나 지연하여 처리해야 되는 일들을 보통 처리
-
물론 그것이 제대로 처리가 되지 않아도 된다는 이야기는 아니기 떄문에 별도라 잘 만들어진 처리기가 필요하다. => 항상 잘 처리되고 유실도 되지 않아야 한다.
why celery?
-
완전 쉽게 연동할 수 있다.
-
우리가 상상하는 모든 기능을 제공한다.
-
일단 남들이 제일 많이 쓴다.
Celery 시작하기
-
먼저 Celery 인스턴스를 생성해준다.
이 인스턴스를 통해 작업 생성 및 작업 관리와 같이 모든 작업의 시작점으로 사용된다.
from celery import Celery
app = Celery('tasks', broker='pyamqp://guest@localhost//')
@app.task
def add(x, y):
return x + y-
tasks라는 Celery 인스턴스를 생성하고 broker의 url을 지정해준다.
함수 비동기 실행하기
from tasks import add
add.delay(1,2)
Worker 실행하기
celery -A tasks worker --loglevel=info
celery 여러가지 기능들
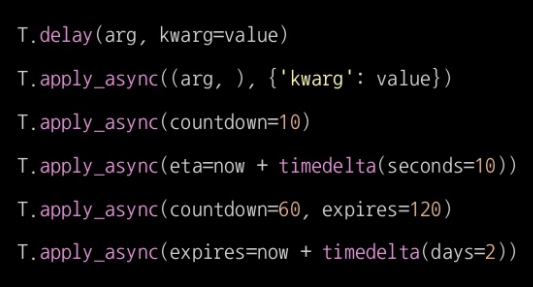
-
실행이 언제 될지 지정할 수도 있다.
# Crontab을 대체할 수 있다.
-
CELERYBEAT_SCHEDULE로 대체
-
+ 버전 관리가 가능하다.
# Celery 상태관리
-
celery event => 쓰기 위해서는 worker를 킬 때 -E 명령어를 같이 써줘야 한다.
-
celery flower
BUT 성장을 위한 가장 큰 문제는 Celery
# 잘 알고 써야 하는 Celery
-
적은 규모에서 간편하게 쓰기에는 더 없이 훌륭하다
-
의외로 조금만 커져도 신경써야 할 부분이 많다.
-
처음부터 고려하지 않으면 알 수 없는 이상 동작처럼 느껴질 수도 있으니 주의가 필요한 부분이 있다.
# Broker
-
어떤 녀석이 일(tasks)를 처리할지 중개 (broker)
-
RabbitMQ - AMQP처럼 동작?
-
AMQP란??
-
RabbitMQ이 가장 default broker이다.
# AMQP
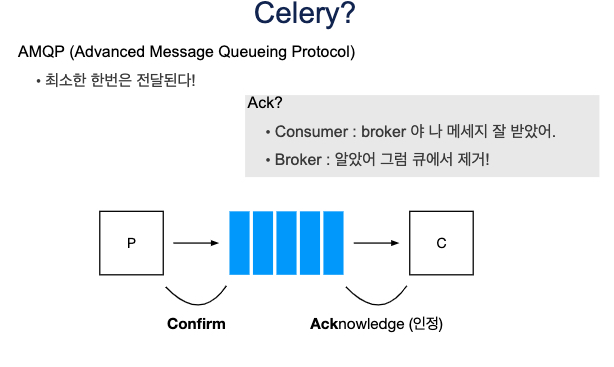
- 최소한 한번은 전달된다.
- But 이 말은 여러번 전달 될 수도 있다.
# 다른 Broker를 쓰면 문제 점(Rabbitmq 가 아닌)
-
ACK
-
visibility_timeout
# ACK
-
worker가 진행한 일에 대한 결과 혹은 상태를 broker에게 전달

-
그럼 broker는 해당 업무를 그냥 done처리해버림
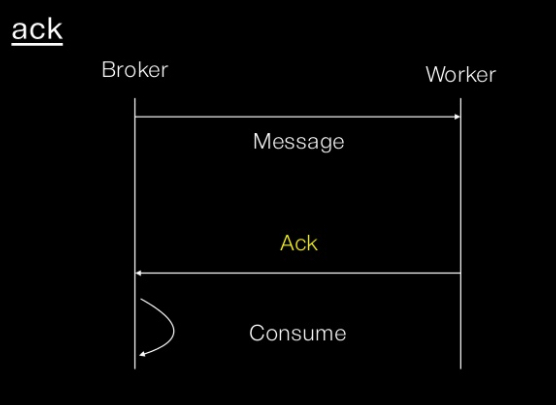
- rabbitmq가 아닌 다른 broker들에서는 visibility_timeout으로 ACK를 구현
# visibility_timeout

# ack + visibility_timeout
-
ack가 오지 않으면 다시 message를 전송한다.
-
이것을 visibility_timeout을 통해서 구현을 해놓음
-
따라서 visibility_timeout내에서 ack가 전달되지 않으면 task가 중복실행된다.
-
eta, countdown 시간보다 visibility_timeout이 커야한다.

# Redis를 broker로 쓸 때
-
Redis는 메모리가 부족한 상황에서 임의로 key를 삭제될 수 있다.
-
즉 task를 받아도 삭제 될 수 있다.
# Celery 구조
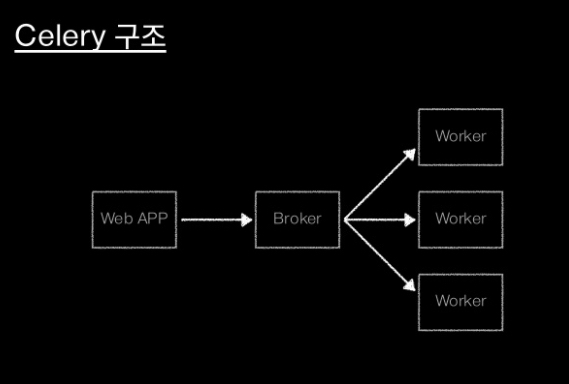
-
web application에서 일을 Broker로 넘긴다.
-
나머지는 Broker가 알아서 Worker로 분배
# prefetch의 배신
-
샐러리의 가장 큰 그림자
-
prefetch는 broker에서 tasks(message)들을 그냥 미리 땡겨두는 거다?
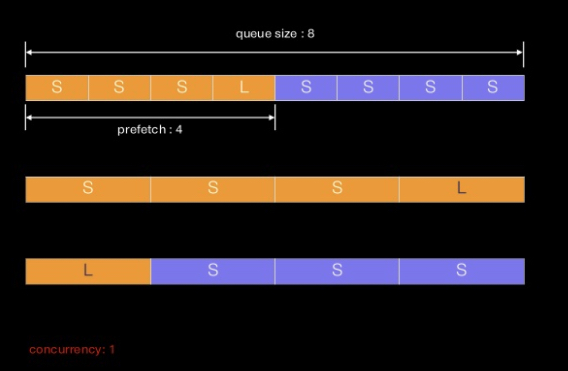
-
Prefetch is a term inherited from AMQP that is often misunderstood by users, The prefetch limit is a limit for the number of tasks (messages) a worker can reserve for itself
-
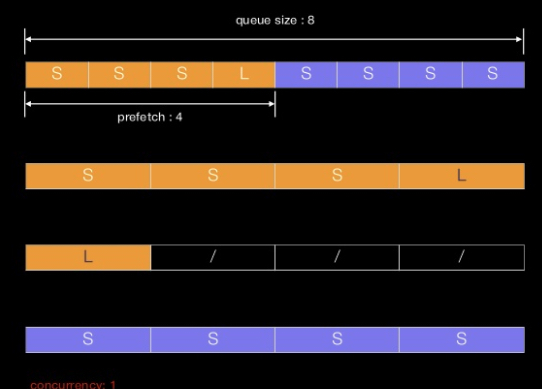
실제 동작은 처음 4개의 공간에 당겨왔던 tasks를 다 끝내야지 이후에 tasks를 가지고 와서 새롭게 시작한다.
-
prefefetch된 단위 전체의 작업을 소비해야(ack) 다음 prefetch가 수행된다.
-
task가 비워지는대로 다음 task를 broker에서 가져올꺼라고는 일반적인 기대와는 다르다.

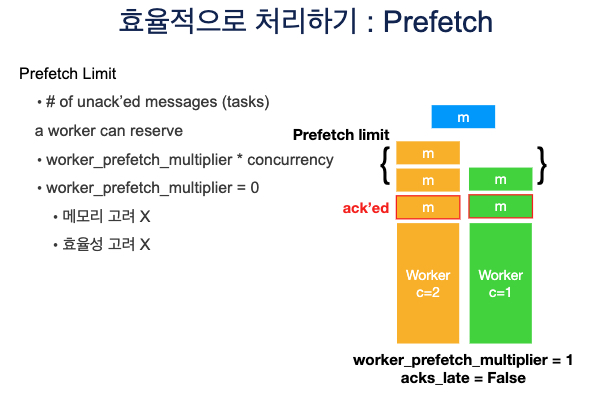
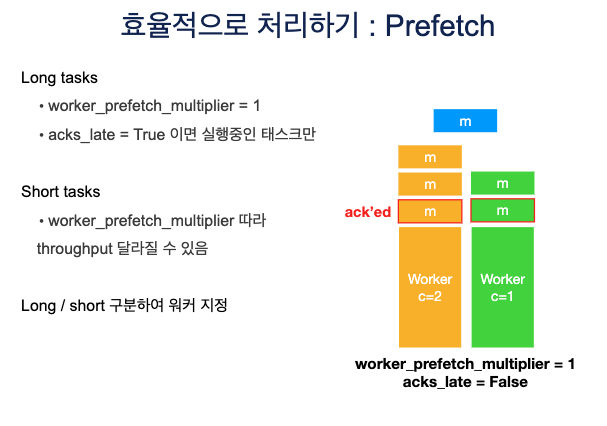
- 긴 task에 대해서는 worker_prefetch_multiplier을 1로 설정해주고, acks_late를 True로 해주면 실행 중인 task 1개를 끝낼 때 마다 떙겨오기 떄문에 불필요 하게 다른 worker들이 쉬게 되는 일이 없다.
# Prefork

-
prefetch limit은 broker에서 worker로 분배하는 로직이고
-
해당 worker안에서 분배하는게 prefork
-
-O fair같은 경우 해당 worker안에서 Master가 분배하는 방법
# Prefork pool prefetch
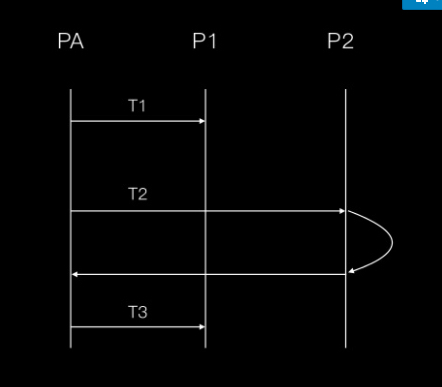
-
현재 일하고 있지 않은 worker에게 일을 주는게 아니라 지속적으로 그냥 순차적으로 쌓아버림
-
-ofair => 일 안하고 있는 worker에서 일을 시킴
해결책
-
task를 한 큐에 담지 마세요
-
prefetch의 특성상 평균 수행 시간이 비슷한 것들이 같은 queue에 있는 것이 성능상 훨씬 유리하다
-
task의 절대적인 수 자체도 중요한 요소이다.
-
처리의 중요도/ 시급도 에 따른 분류도 중요하다
-
위와 같은 요소를 고려해서 Queue를 나눠주세요
-
CELERY ROUTE
-
worker를 특정 queue를 붙여 둔다.
정말 간단한데 성능에 큰 영향을 주는 또 다른 요소
-
ingore_result => 이게 default로 켜져있다.
-
Celery는 기본적으로 수행 결과(return)을 저장 해야 작업이 끝난다.
-
하지만 대부분 TASK내에서 직접 결과를 다른 곳에 저장하지, return 자체를 쓰는 경우는 드물다.
-
보통은 TASK 연계를 하는 경우만 필요하다.
-
결과를 저장하는 비용이 적지 않기 때문에 이걸 끄기만 해도 무척 성능이 좋아진다.
'Django' 카테고리의 다른 글
| 주니어 개발자의 Django ORM 수난기 (5) | 2020.07.21 |
|---|---|
| django celery beat crontab time 설정 (0) | 2020.05.14 |
| Django ORM 성능 개선하기(실제 서비스에서) (1) | 2020.05.04 |
| 장고 모델 생성시간 지정해주기 (0) | 2020.04.01 |
| django celery extension(django-celery-results) (0) | 2020.03.17 |